AI Software Engineering benchmark just went from 80% to 23%
What is SWE-bench?
SWE-bench is a widely followed benchmark evaluation framework designed to test AI coding assistants on real software engineering tasks.
AI coding assistant benchmarks are supposed to give us clarity. SWE-bench does the opposite.
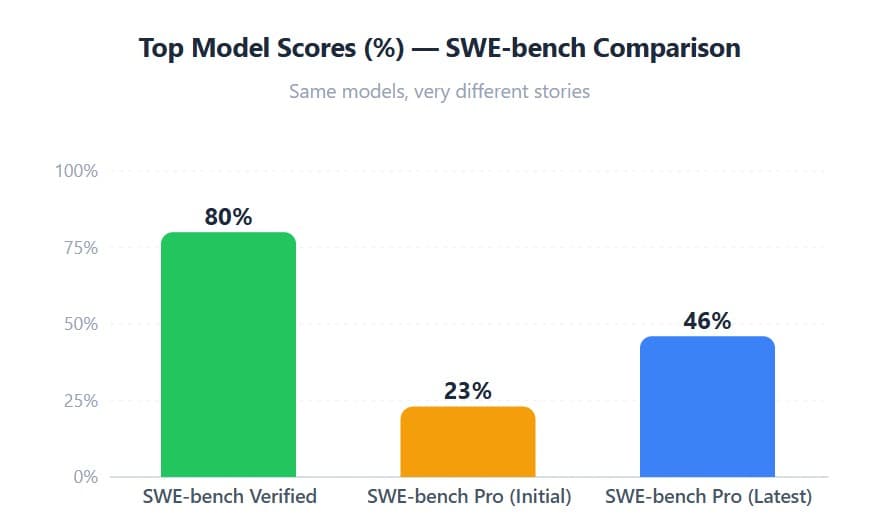
SWE-bench-Verified has been widely considered a Python-language-only, 500-task benchmark, where the best models recently reached around an 80% score (roughly 400 out of 500 tasks solved). The industry celebrated
Then Scale AI introduced SWE-bench-Pro: harder tasks, multiple programming languages, and more realistic, real-world software engineering scenarios. Suddenly, the same frontier models crashed to around a 23% score 😬
But wait - it gets better.
Someone noticed that the 23% score was calculated using a “capped turn limit and capped cost”. Give the models more attempts and an uncapped budget? The best-performing models jumped to ~46%. Same benchmark. Same models.
Benchmarks keep shifting, evaluation rules keep changing, and scores keep flip-flopping. The industry needs standardized, stable evaluation protocols.
Before we benchmark models, we need to benchmark the benchmarks.
Reference: https://scale.com/leaderboard/swe_bench_pro_public



